Email How-To Tip |
By Robert Graf-Waczenski
Senior Applications Programmer, L-Soft
The new ability of LISTSERV Maestro 11.0 to attach the delivery of a mail job directly to running a subscriber data import makes many use cases possible that have been difficult to implement with earlier versions of the software. This tip describes how to use this option and how to benefit the most from it.
Subscriber data imports (in the form of one-time imports or reusable importers) are a powerful tool to connect with external databases and to load or update subscriber lists in the LISTSERV Maestro subscriber warehouse. Used as an alternative or in combination with the automatically provided public subscriber website that comes with each list group, such an import makes data from your external database available for the purposes of email marketing jobs in LISTSERV Maestro.
The query logic that defines the set of imported data can be as complex as desired, which allows you to define many different subscriber lists that correspond to a variety of data subsets that may exist in the external database. Each such subset may require sophisticated logic that uses attributes that are not visible or necessary in the subscriber list.
Once set up and running properly, the execution of a data import establishes a properly synchronized state in the sense that the data in the subscriber list reflects the state of the data in the external database at the moment in time directly after the import. Delivering a mail job to all subscribers on the list shortly after having run the import will then utilize the data that was imported.
If the data in your database changes over time, to make sure that the job delivery uses the most recent state of the data in your database, you can for example (either manually or via an external trigger) run the importer again each time when you plan to send a mail job. By choosing the "Full Synchronize" option in the importer settings, you can also make sure that any records that are not included in your database query are also removed from the subscriber list, which means that your subscriber list is a synchronized copy of your database query.
Personalized Recommendations
Suppose you run an online bookstore and plan to integrate LISTSERV Maestro with the shop system database using SQL queries. By analyzing customers' past purchases and browsing history, you can generate personalized book recommendations in your email campaigns. Subscriber data imports enable you to extract a set of email addresses based on information such as genres or authors. This personalization boosts customer engagement and increases the likelihood of conversions.
Example SQL Query:
|
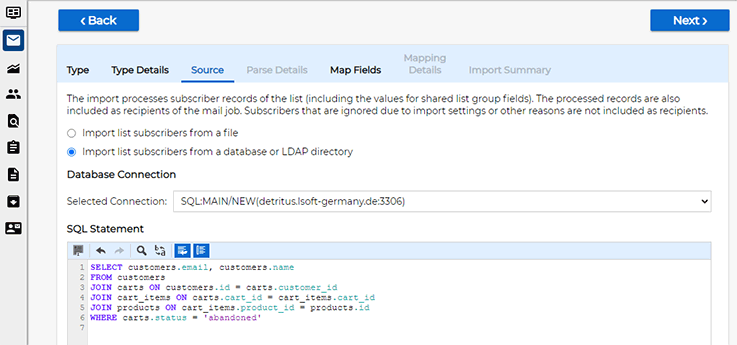
SELECT customers.email, customers.name |
This query will return the set of email addresses of customers who purchased a book by a given author. The plan is to run an email campaign that announces the release of a new book by that author. Similar campaigns are also planned for other popular authors, but each of these campaigns is targeted at customers who already purchased a book by that author previously to maximize conversions.
Abandoned Cart Recovery
Another effective use case is recovering abandoned carts through email reminders. By integrating your subscriber list with the shop system database using subscriber data imports, you can identify customers who have left items in their carts without completing the purchase. Sending targeted emails with reminders, personalized incentives, or limited-time discounts can help recapture their attention and drive them back to complete the purchase.
Example SQL Query:
|
SELECT customers.email, customers.name |
If you decide to use the "Send to a Subscriber List in the Subscriber Warehouse" option to implement campaigns like those in the examples above, you are facing challenges:
1. Volatile Data: A property common to both examples is that the queries yield data that typically changes a lot over time. With LISTSERV Maestro 10.1 or earlier, the volatile nature of the data would force you to create subscriber lists specifically for each query and use these lists exclusively for the purposes of the mail jobs associated with these campaigns.
2. Scheduling Issues: While the SQL shown in the examples above looks fairly trivial, in reality such queries often need to consider complex data structures and large data volumes, which translates to long and often unpredictable import times.
You can address the first problem by purging and re-populating the list (or lists) each time you plan to deliver a mail job. This, however, has serious implications for reporting. Discarding the data that was imported for a previous similar campaign makes subscriber-level reporting and follow-up mailings impossible. At the same time, you cannot simply leave the data in the lists. Otherwise, you are facing the risk of sending campaign messages to the wrong set of addresses.
To address the second problem, you can aim at scheduling your email campaigns with a suitable time delay after executing the associated imports.
LISTSERV Maestro 11.0 comes with a new option that was tailored to address the problems described above. While it's still possible to create subscriber lists as one-to-one mirrors of datasets in your external database, the new option described below allows you to design your subscriber lists to reflect customers with their personal attributes only and code the sophisticated logic about previous purchases or other types of behavior into the queries of subscriber data importers (or, if necessary due to policy or infrastructure reasons, into the logic that creates just-in-time server files that your importers are reading from).
To use the new option, open the "Recipient Definition" workflow step of a LISTSERV Maestro mail job:
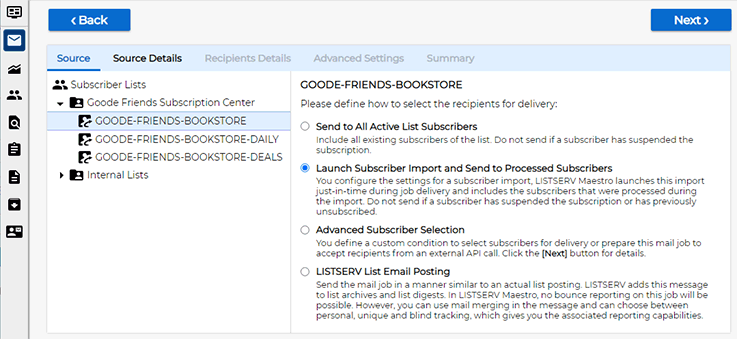
Selecting this new option tells LISTSERV Maestro that you plan to define an import or plan to use an already existing importer to be run in sync with the delivery of the mail job.
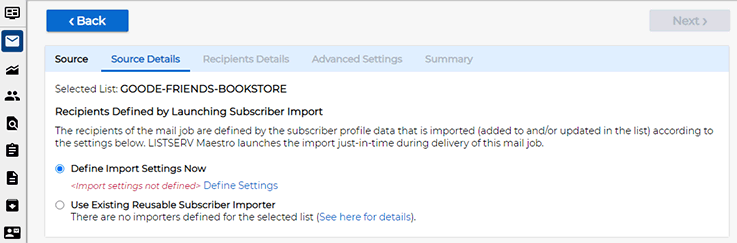
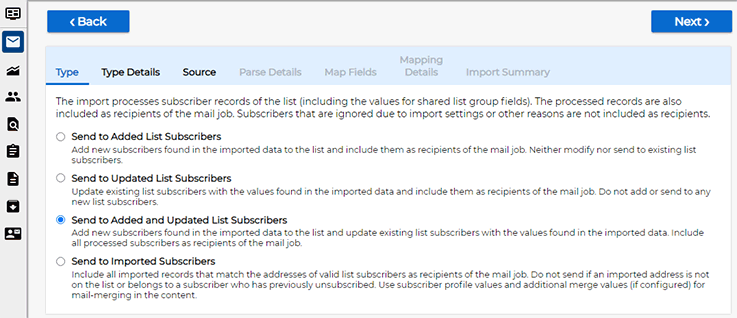
In this tip, we will be defining a one-time import. Click on the "Define Settings" link under "Define Import Settings Now". The wizard now branches into the import wizard with some special settings:
Proceed to the "Source" screen and enter the database query:
On the "Map Fields" screen, you map the queried fields to the list fields, just as you would with any other import:
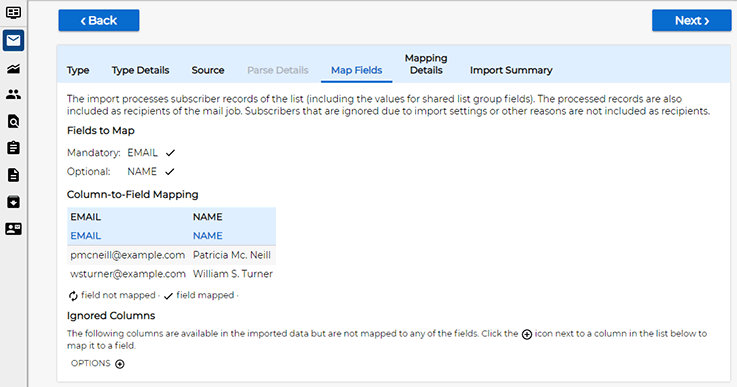
The "Import Summary" screen summarizes the settings:
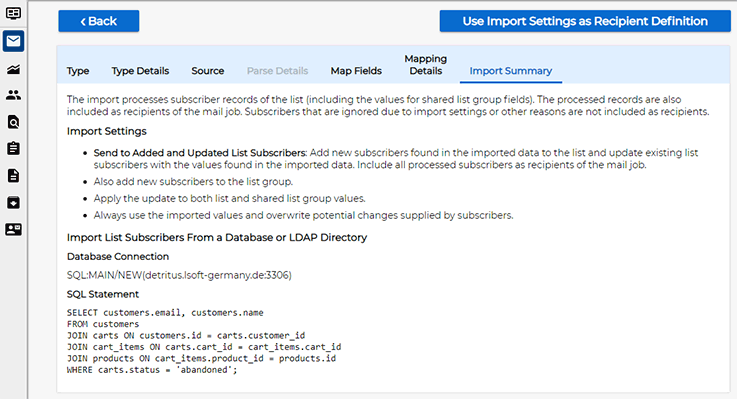
Click the "Use Import Settings as Recipients Definition" button to return to the recipient wizard:
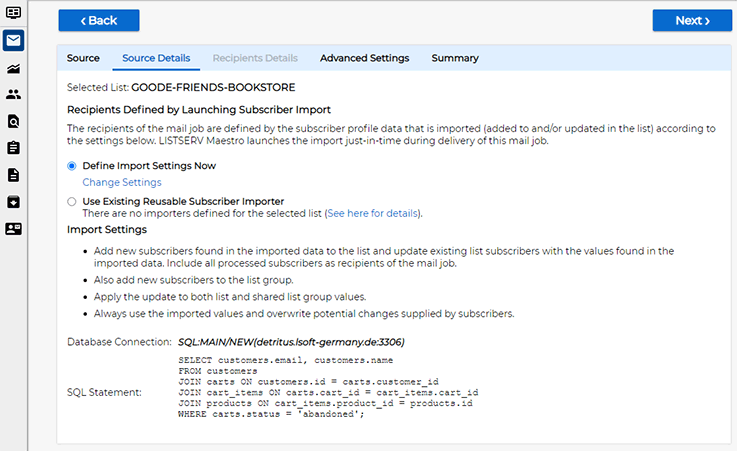
Proceed to the "Summary" screen of the recipients wizard:
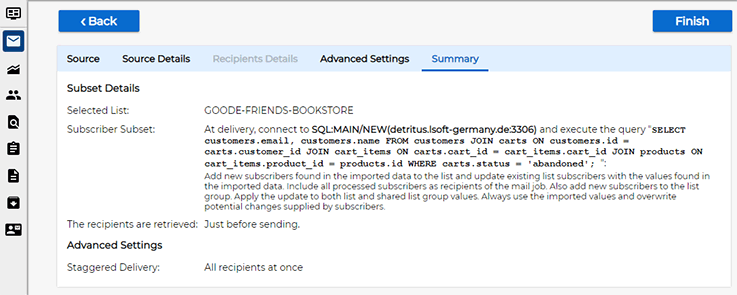
As with any other method to define recipients, click the "Finish" button to apply the settings to your mail job.
Examples like the ones described in this tip are typical cases where manually scheduled imports that maintain a mirrored copy of a dataset in an external database fall short. The new option in the recipients wizard has some key properties:
With the new option available, you no longer must design subscriber lists specifically for certain email campaigns. Instead, you can configure your subscriber lists to store personal attributes only, optionally augmented with some additional generic information that you may want to use frequently in mailings, such as customer categories or other preferences that you either can populate with manually scheduled imports or collect from users who log in to the public subscriber website.
Especially for campaigns based on volatile data like the abandoned cart recovery example described in this tip, purging and re-populating the same list with a new dataset from the external database each time before a mail job is delivered means that you cannot benefit from any of the advantages of using a subscriber list, such as subscriber-level reporting and follow-up mailings, both of which require that you keep subscriber records of previous mail jobs in the list. The ability to do just that is the main reason why the new option was implemented in LISTSERV Maestro 11.0
Was this article helpful to you? Would you recommend it to a colleague? Your input helps us create content that truly supports your work. Thank you!
|
Want More Insights? Catch up with the latest LISTSERV developments, industry best practices, expert tips, tutorials and more. |
LISTSERV is a registered trademark licensed to L-Soft international, Inc.
See Guidelines for Proper Usage of the LISTSERV Trademark for more details.
All other trademarks, both marked and unmarked, are the property of their respective owners.



