Section 1
Introduction
Section 2
The Maestro Interface
Section 3
Defining a Job
4.4 Recipients Details
Section 5
Defining Content
Section 6
Defining Tracking
Section 7
Sender and Delivery Options
Section 8
Outbox
Section 9
Delivered Jobs
Section 10
Reporting and Statistics
Section 11
User Settings
Appendix A
24 Hour Clock
Appendix B
International Character Sets
Appendix C
Comma Separated Files
Appendix D
AOL Rich Text
Once LISTSERV Maestro can successfully separate the recipient data into columns, or otherwise quantify the data, the next steps are to define the column that identifies the e-mail address, decide whether to use additional recipients data for mail merging and tracking, and to edit the column headers, if necessary. The Recipients Details screen is split into three sections to accommodate these steps.
4.4.1 Usage of Recipients Data
LISTSERV Maestro needs to know if additional recipient data will be used for mail merging and tracking, or whether this information is to be ignored and the job sent as bulk e-mail. If the "Use additional recipient data for mail merging and tracking" option button is selected, columns from the text file or database can be used in the e-mail message to create personalized messages. These columns can then also be used to identify recipients for more detailed tracking reports. For more information in this guide on using mail merging, see Section 5.6 Merge Fields and Conditional Blocks.
If the "Ignore additional recipient data and send job as bulk e-mail" option button is selected, any additional columns that were uploaded with the file or that appear in the database will be ignored by the system. It will not be possible to use mail merging. Tracking for the message will be limited to "blind" tracking, meaning that the tracking data available from the job will not be associated with identifiable individuals or other demographic information.
4.4.2 Recipient Identification Columns
In order to process an e-mail job, LISTSERV Maestro needs to know which column represents the recipients' e-mail addresses. If LISTSERV Maestro has used an uploaded text file, a database, or a LISTSERV defined database, it is necessary to identify the column for e-mail address, and optionally, the column for name. Use the pull-down menus to select the E-mail Column and the Name Column.
If a text file or a database was used to define recipients, it is possible to add or edit the "headers." Headers are specially defined rows in databases. Headers are used by database tables to label the columns of data so that the system and the user can correctly identify the columns. Recipient data files containing a header will be sorted or parsed by LISTSERV Maestro based on that header row, and the table reflected on the screen will have the columns labeled. If the recipient data file does not contain a header, it is possible to define a header within LISTSERV Maestro.
Figure 18 Recipients Details for Uploaded Text File and Database
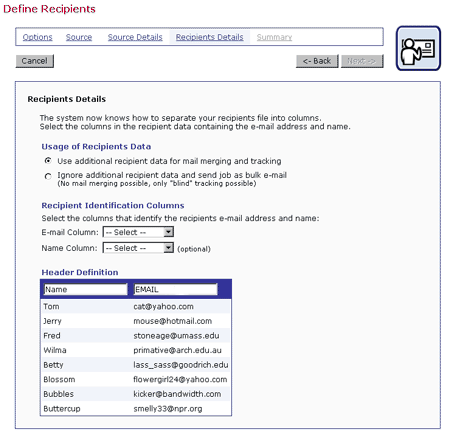
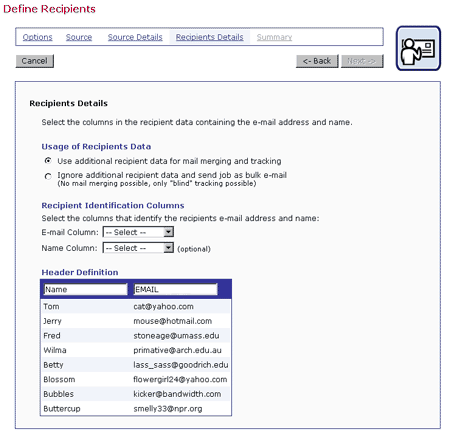
Header labels are limited to upper and lower case letters, the numbers 0-9 and the underscore "_". Any illegal characters in the headers will have to be changed before proceeding. Before continuing to the next screen, specify the "E-mail Column" and the "Name Column" using the pull down menus.
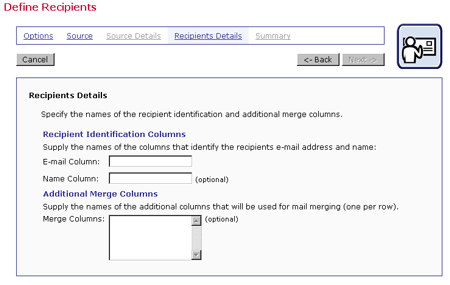
For a LISTSERV List, the E-mail column and the name column are preset to *TO and NAME, respectively. There is a text box to input additional mail merge columns. For a LISTSERV selected database, fill in the name of the e-mail column and the name column in the text boxes. Additional columns (if any) will have to be identified as well if they are to be used for merged content.
Figure 19 Recipients Details from LISTSERV List
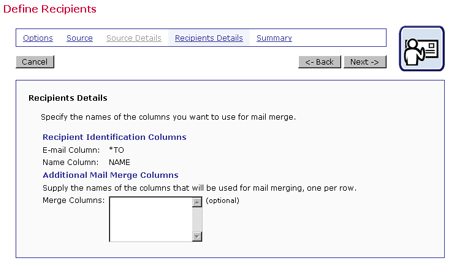
Figure 20 Recipients Details from LISTSERV Selected Database
Click the Next -> button to continue.. An "Operation in Progress" message will appear during the processing time. When the operation has concluded successfully, the Summary screen will open.